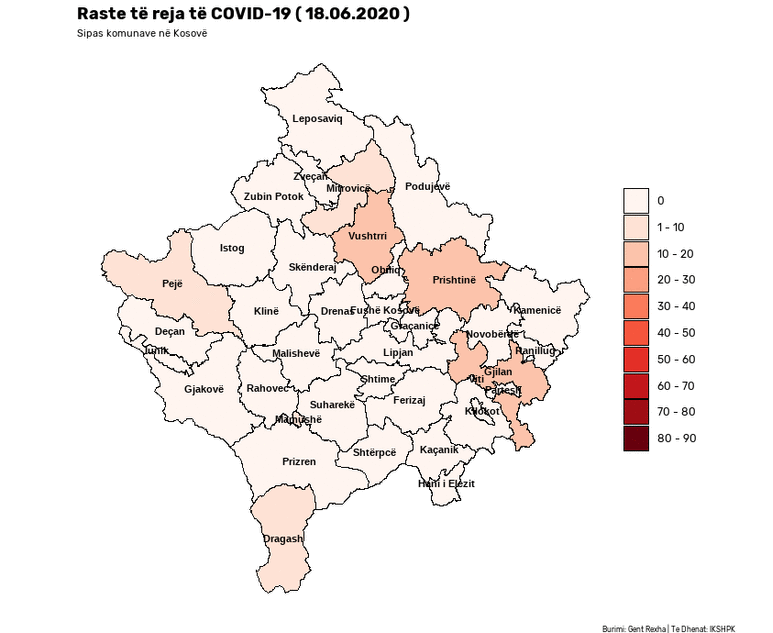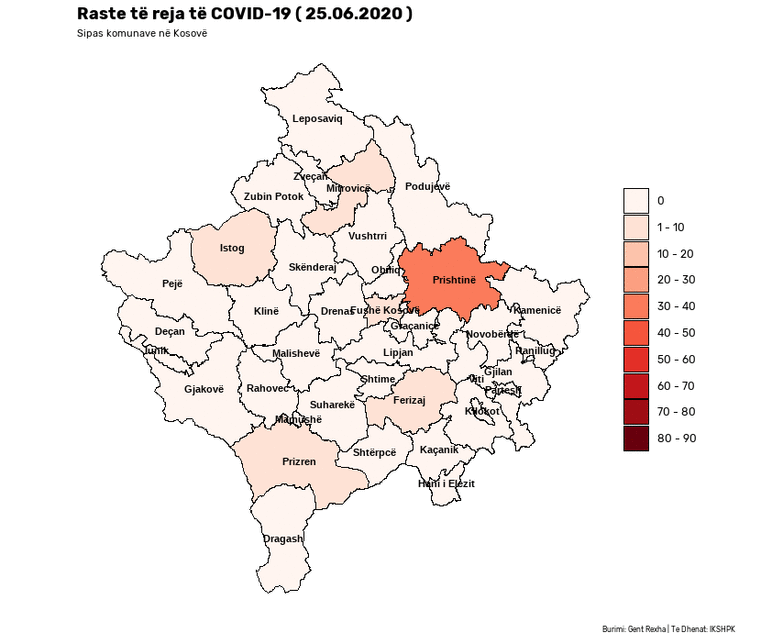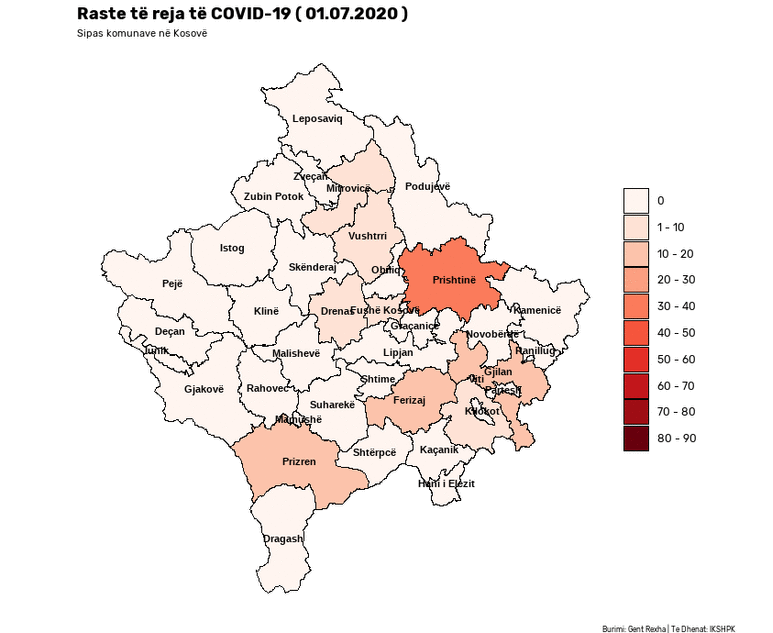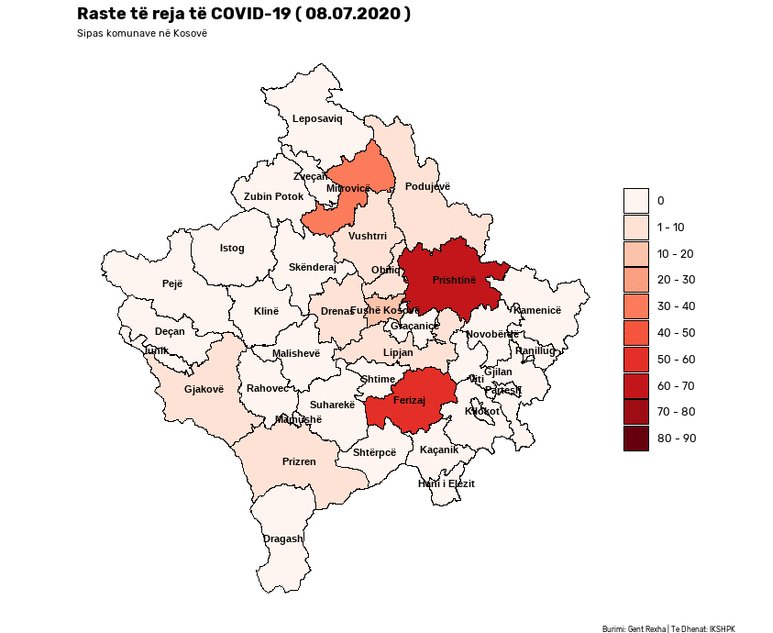
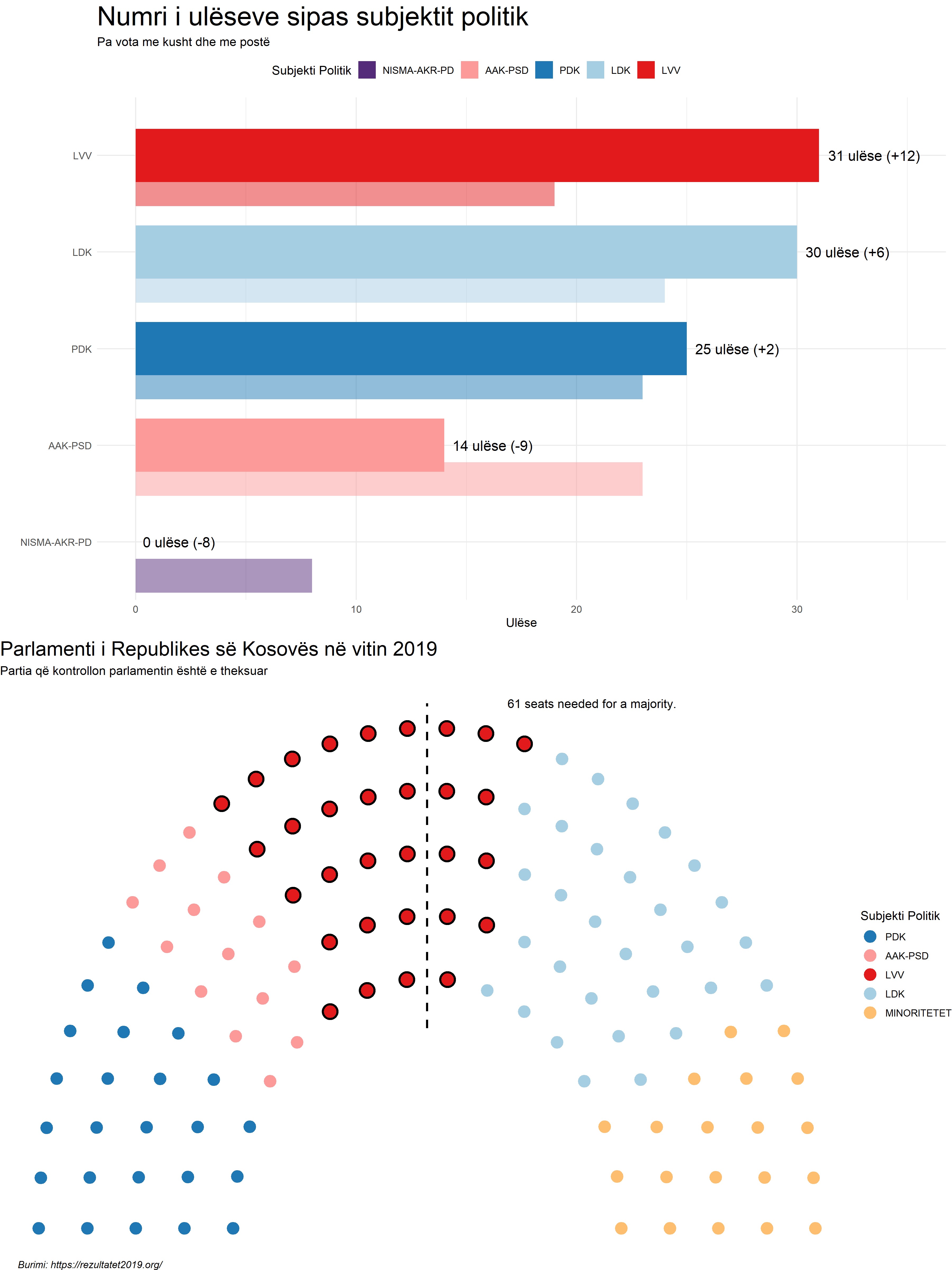
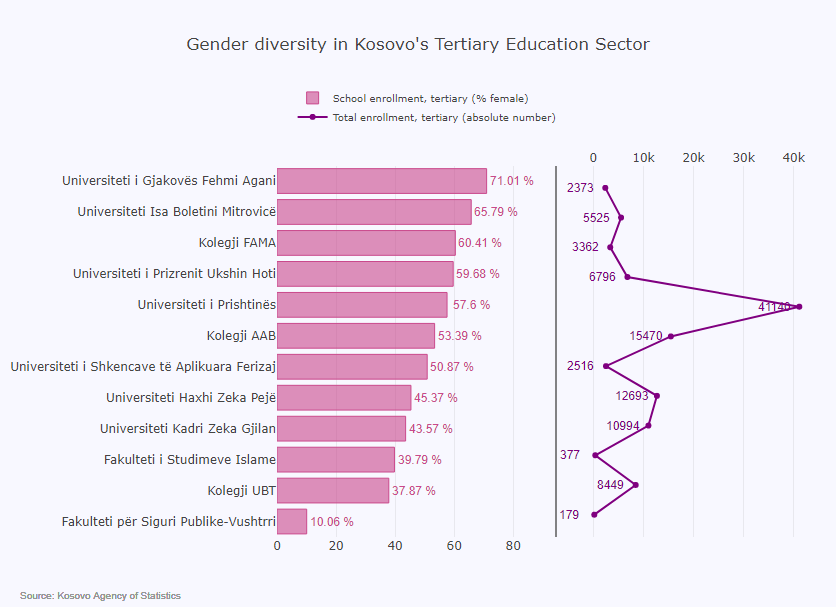
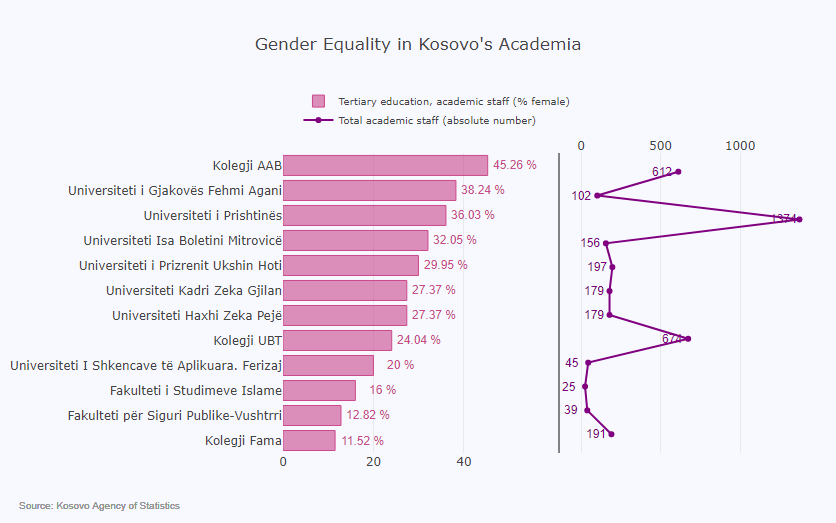
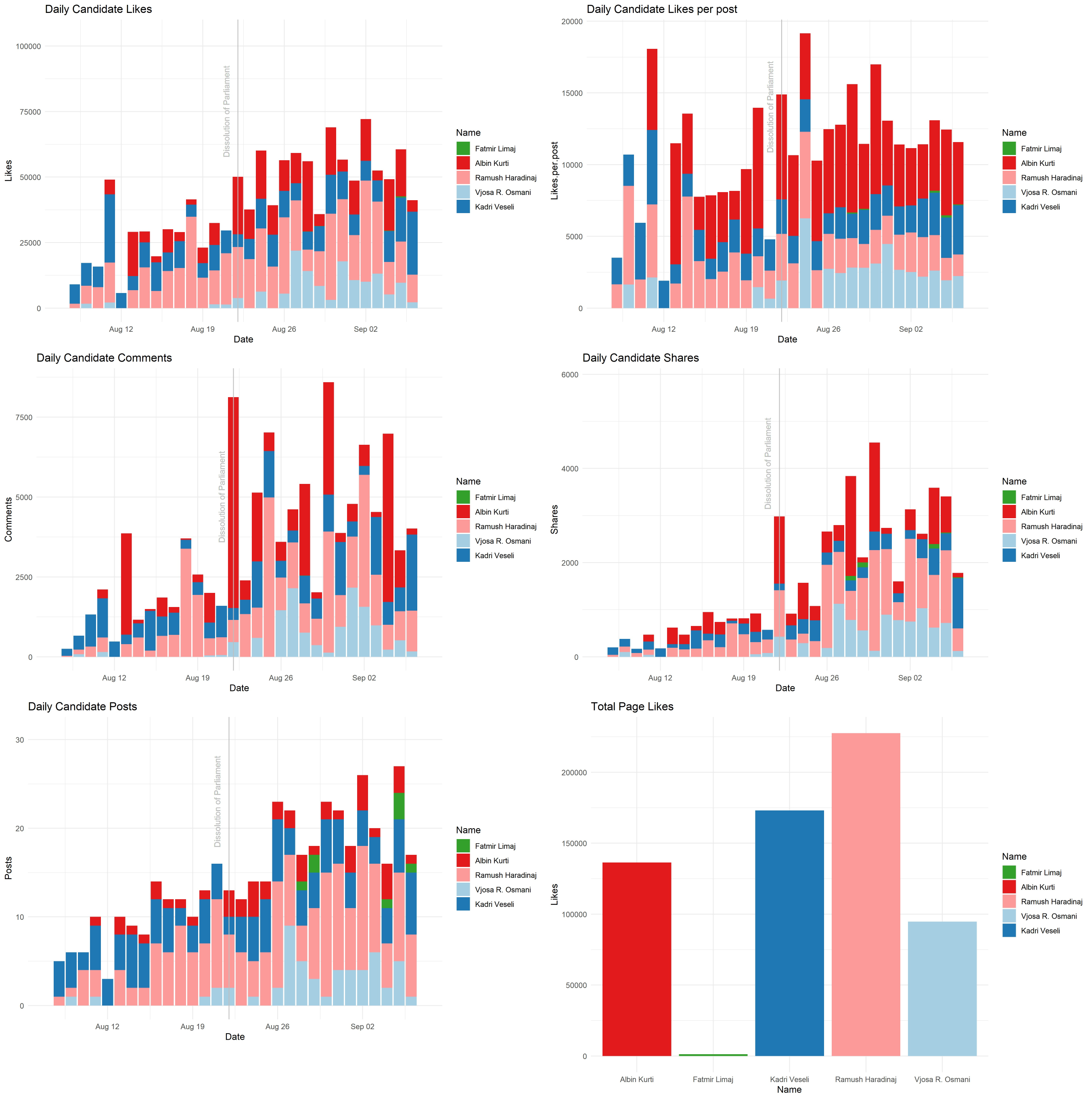
This notebook presents a Satirical News Detection and Analysis in Albanian, which uses news articles taken from the Albanian News Article Dataset from two separate sources: (1) Kungulli.com and (2) Kallxo.com, and predicts the type of article using supervised Machine Learning (ML).

The experiment was carried out utilizing a Cross-validation (5-fold) setup for internal validation, referred as the training score, and an external testing set for external validation, referred as the testing score. Evaluation includes multiple classifiers, scaling methods, and various article content preprocessing approaches
In summary, this approach combined different classifiers, scaling methods, and text preprocessing approaches to find the best performing pipeline for handling satirical news classification in Albanian, attaining a test set accuracy score of 0.975. To the best of my knowledge, this kind of study has never been published before, and it lays the groundwork for future research in this area, as well as potential expansion to automated fake news detection in Albanian, assuming the necessary data can be obtained.
The notebook can be accessed here: https://www.kaggle.com/gentrexha/satirical-news-detection-and-analysis-in-albanian.
]]>